宝盈国际配资 SkyReels V3三大多模态能力登顶行业SOTA,重新定义视频生成新范式


当AIGC技术从 “单点突破” 迈入 “全场景落地” 的深水区,视频生成赛道正经历着前所未有的变革:用户对生成内容的 “可控性、连贯性、创意延展性” 要求持续升级,从单一图像转视频到多模态协同创作,从秒级片段生成到分钟级叙事表达,从基础风格迁移到精细化编辑增改,市场亟需能够覆盖全场景需求、兼顾技术深度与用户体验的一体化解决方案。
在闭源模型垄断核心技术、开源方案面临效果与效率失衡的行业现状下,昆仑万维(300418)11月初刚推出的SkyReels V3多模态视频生成模型,以 “一核多支” 的技术架构(统一 Multi-modal In Context Learning 预训练框架 + 三大子任务精调优化),全面覆盖图片参考、音频参考、视频参考三大核心场景,用突破性技术打破行业瓶颈,重新定义多模态视频生成的能力边界。
SkyReels V3代表一系列多模态视频生成模型,包括基于图片参考、音频参考和视频参考的视频生成。该系列模型都基于同一个Multi-modal In Context Learning框架预训练模型,然后再进行子任务精调进一步训练适配优化。
当前,SkyReels V3多模态视频生成模型全面接入SkyReels。SkyReels强势聚合全球顶尖AI多模态模型,涵盖Google Veo 3.1、Sora 2、Runway、Nano Banana、GPT Image、Seedream 4.0等国内外主流模型,并且一站式提供图片生成、视频生成、数字人、音乐生成等多种AI创作方式。
欢迎全球用户使用SkyReels:
https://www.skyreels.ai
01
基于多主体参考图像的视频生成能力
SkyReels V3包括基于多主体参考图像的视频生成模型,其能够依据多张主体与背景参考图像,结合用户输入的提示语,生成符合组合关系与情节发展的视频片段。
该模型在实现高度主体一致性与背景一致性的同时,精准响应用户指令要求。为增强模型对参考图像的内容保持能力,SkyReels团队构建了一套完整的数据处理流程,采用跨帧配对(cross-pair)策略从连续视频中选取参考帧,并借助图像编辑模型提取主体图像,同步完成背景补全与语义改写,有效规避“复制粘贴”效应。
在模型训练阶段,SkyReels团队引入图像-视频混合训练机制,并支持多分辨率联合训练,从而显著提升模型的泛化性能。自SkyReels V2版本演进至V3版本以来,该模型在多项评估指标上已达到行业闭源SOTA(state-of-the-art)模型水平,展现出业界领先的综合生成能力。

图丨SkyReels-V3与行业SOTA模型在多主体参考视频生成上的定量指标对比
02
基于音频参考的视频生成能力
基于今年8月发布的音频驱动数字人模型SkyReels A3,SkyReels团队发布更先进的基于音频参考的视频生成模型。
对于用户上传的音频和图像,SkyReels V3模型可以生成嘴部对齐的高清视频片段。除了进一步优化音画对齐和画面质量外,并成为业内首个支持单镜头多人多轮对话的数字人模型。
SkyReels团队通过引入区域路由机制,支持用户指定画面中的若干角色进行说话,同时,将模型输入的多段带角色标签的音频依次时序拼接,从而实现自然流程的多轮对话。

为了满足用户创作需求,SkyReels V3模型还支持多种复杂运镜组合,有效提升视频艺术质量和观赏性。具体来说,我们通过输入相机运动参数的监督学习,使得模型既支持同一时间多个运镜组合控制,也支持不同时间运镜的丝滑切换。
此外,通过关键帧插帧范式,支持不同动作幅度,分钟级别高质量视频生成。对于超长视频,模型会首先生成等间隔的关键帧,从而确定整个视频的动作框架,再将关键帧和当前音频作为条件,生成不同的嘴部一致的中间视频片段。运动幅度则通过控制给定参考图的位置编码——其和关键帧的距离,来进行控制。
相关自动化评测指标显示,在相同分辨率生成场景,模型在声音画面同步(Sync-C和Sync-D),视频画面质量(IQA和ASE)效果接近主流闭源SOTA视频模型,相比开源模型有显著优势。
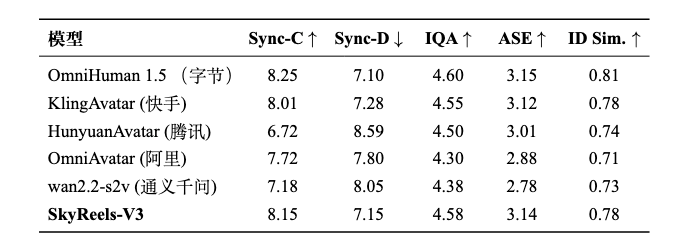
图丨SkyReels-V3模型和当前主流视频生成模型在数字人生成场景的定量指标结果对比
03
基于视频参考的视频生成能力
SkyReels V3支持视频参考的视频任务,包括视频延长、视频编辑和视频风格化。为了同时支持这三个任务的视频生成,以及针对视频参考的成本,SkyReels团队做了一些模型上的改进。
首先,由于三个任务对于条件的理解不完全一样,针对参考视频和生成视频的关系设计的不同的空间位置编码,和任务特定嵌入,让模型学会统一的去理解这些任务。
同时,为了减少总的token数量,我们结合了token concat的灵活性和channel concat的高效性,降低了总体的token数量同时保证了生产的效果。此外,我们通过历史增强的办法,让模型能做到分钟级别的延长效果。
视频延长能力不再局限于“单镜头拉长”的传统方式,而是基于视频语义和用户 Prompt,智能预测下一个镜头的合理延续与场景内容。模型支持单镜头延长和多种切镜延长方式(如 Cut-In、Cut-Out、Reverse Shot、Multi-Angle、Cut Away 等),能自动生成具备叙事逻辑与视觉连贯性的延展片段,让镜头语言更丰富,画面更具动感与电影感。SkyReel V3在单镜头延长和切镜延长等方面均达到行业SOTA水平。

视频编辑能力具备多模态输入的增删改替能力,其中多模态输入包括编辑指令、mask区域、编辑参考图。用户不仅能进行指令来让模型进行随意的编辑,同时还可以基于多模态条件做更精细化的控制。目前该功能正在准备上线。
视频风格化能力的主要挑战在于高质量风格化数据对的稀缺性。为此,我们创新性地构建了一套端到端自动化的风格化数据生成与筛选流程,该流程协同先进图像编辑模型与ControlNet的可控生成能力,实现了从无到有的高质量配对数据生成。通过引入基于多模态模型的过滤机制,确保数据兼具艺术性与训练可用性,为视频风格化模型的规模化训练与艺术可控性提供了可扩展、高质量的数据支撑。

04
结语
从图片到音频再到视频的全场景覆盖,从单任务生成到多模态协同创作,SkyReels V3的推出不仅是昆仑万维在AIGC领域的技术深耕与实力彰显,更为视频创作行业注入了全新的革新动能。
在内容生产日益追求高效、个性化、专业化的今天,SkyReels V3以多项行业SOTA级别的技术表现,既解决了闭源模型 “黑箱操作、成本高昂” 的痛点,又弥补了开源方案 “效果有限、场景单一” 的短板,让分钟级高质量视频生成、多轮对话数字人创作、电影级镜头延展等曾遥不可及的功能,成为普通创作者触手可及的工具。
未来,SkyReels V3将持续以技术创新为核心,不断拓展多模态视频生成的应用边界,推动内容创作从 “工具赋能” 向 “智能共生” 演进,为影视制作、数字营销、自媒体创作等领域带来更高效、更具创意的生产范式,助力每个创作者释放无限创意潜能,共同开启视频生成的全新时代。
嘉正网提示:文章来自网络,不代表本站观点。
- 上一篇:恒捷配资 燃油车会被淘汰吗?看看修车店老板怎么说,你也许就清楚了!
- 下一篇:没有了